

버블 정렬(Bubble sort)
서로 인접한 두 수를 비교하여 정렬하는 알고리즘이다.
- 시간복잡도 : O(n2)

public void bubble_sort(int arr[], int n) {
for (int i = n - 1; i > 0; i--) {
for (int j = 0; j < i; j++) {
if (arr[j] > arr[j + 1]) {
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}}}}
선택 정렬(Seleciton sort)
① 정렬되지 않은 부분 중 최소값을 찾는다.
② 그 값을 정렬되지 않은 부분의 맨 앞의 수와 교체한다.
③ 정렬된 부분을 제외한 나머지 리스트를 같은 방법으로 교체한다.
- 시간복잡도 : O(n2)

public void selection_sort(int arr[], int n) {
for (int i = 0; i < n - 1; i++) {
int min = i; // 최소값을 저장할 변수
for (int j = i + 1; j < n; j++) {
if (arr[j] < arr[min])
min = j;
}
if (i != min) {
int tmp = arr[i];
arr[i] = arr[min];
arr[min] = tmp;
}}}
삽입 정렬 (Insertion sort)
두 번째 원소부터 시작하여 앞(왼쪽)의 원소들과 비교하여 삽입할 위치를 지정한 후, 지정한 자리에 데이터를 삽입하여 정렬하는 알고리즘이다.
- 최선의 경우 시간복잡도 :O(n) ➡️ 이미 정렬되어 있는 경우
- 최악의 경우 시간복잡도 : O(n2) ➡️ 입력 자료가 역순일 경우
① 두 번째 수부터 자신의 왼쪽 수와 비교하여 더 작으면 왼쪽 이동, 크면 위치 유지
② 왼쪽으로 이동했으면, 다시 자신의 왼쪽 수와 비교 반복
③ 위치를 유지했으면 다음 원소를 기준으로 하여 왼쪽 수와 비교 반복

public void insertion_sort(int[] arr, int n) {
for (int i = 1; i < n; i++) {
for(int j = i; j > 0; j--) {
if(arr[j] < arr[j-1]) {
// 한 칸씩 왼쪽으로 이동
int temp = arr[j];
arr[j] = arr[j-1];
arr[j-1] = temp;
}
else break; // 자신보다 작은 데이터를 만나면 그 위치에서 break
}
}
}
합병 정렬(merge sort)
하나의 배열을 두 개의 균등한 크기로 분할하고 분할된 부분 배열을 정렬한 다음, 두 개의 정렬된 부분 배열을 합하여 전체를 정렬하는 알고리즘이다.
1. 분할(Divide) : 배열을 같은 크기의 2개의 부분 배열로 분할
2. 정복(Conquer) : 부분 배열 정렬. 순환 호출을 이용하여 다시 분할-정복 방법을 적용한다.
3. 결합(Combine) : 정렬된 부분 배열들을 하나의 배열에 합병
- 시간복잡도 : O(nlog2n)
- 평균과 최선, 최악의 경우 모두 같은 시간복잡도를가진다.

static int[] sortArr; // 정렬한 리스트를 담을 임시배열
public static void merge(int[] arr, int left, int mid, int right){
/* 2개의 부분배열 arr[left ... mid] 와 arr[mid+1 ... right] 의 합병정렬 */
int i = left; // 정렬된 왼쪽 리스트에 대한 인덱스
int j = mid + 1; // 정렬된 오른쪽 리스트에 대한 인덱스
int k = left; // 정렬될 리스트에 대한 인덱스
sortArr = new int [arr.length];
while(i<=mid && j<=right){
if(arr[i] <= arr[j])
sortArr[k++] = arr[i++];
else
sortArr[k++] = arr[j++];
}
// 남아있는 값들 일괄 복사
if(i>mid) {
for(int l = j; l<=right;l++)
sortArr[k++] = arr[l];
} else {
for(int l = i; l <=mid;l++)
sortArr[k++] = arr[l];
}
// 임시배열 (sortArr)의 리스트를 배열 arr로 재복사
for(int l=left; l<=right; l++){
arr[l] = sortArr[l];
}}
public static void merge_sort(int[] arr, int left, int right){
if(left < right) {
int mid = (left + right) /2; // 리스트를 균등한 크기로 분할 (Divide)
merge_sort(arr, left, mid); // 앞 부분 배열 정렬 (Conquer)
merge_sort(arr, mid+1, right); // 뒷 부분 배열 정렬 (Conquer)
merge(arr, left, mid, right); // 정렬된 2개의 부분 배열을 합병 (Combine)
}}
public static void main(String[] args) throws IOException {
int[] arr = {5,4,3,2,6};
merge_sort(arr, 0, arr.length-1);
for(int i : arr){
System.out.println(i);
}}
힙 정렬 (heap sort)
완전 이진 트리의 일종으로 우선순위 큐를 위하여 만들어진 정렬 알고리즘이다.
내림차순 정렬을 위해 최대 힙을 구성하고 오름차순 정렬을 위해 최소 힙을 구성하면 된다.➡️ 최대값, 최솟값을 쉽게 추출
- 시간복잡도 : O(nlog2n)
- 평균과 최선, 최악의 경우 모두 같은 시간복잡도를가진다.

퀵 정렬(Quick sort)
분할-정복 알고리즘의 하나로, 평균적으로 매우 빠른 수행 속도를 자랑한다. 합병 정렬(merge sort)과 달리 퀵 정렬은 배열을 비균등하게 분할한다.
1. 배열 내 임의의 기준인 피벗pivot값을 정하고 해당 피벗 기준으로 두 개의 부분 배열로 나눈다.
2. 한쪽 부분에는 피벗 값보다 작은 값들만, 다른 한 쪽은 큰 값들만 넣는다 (안전성 보장X)
3. 분할된 부분 배열에 대해 순환 호출을 이용해 정렬. 다시 피벗 값을 정하고 부분 배열로 나누는 과정 반복
- 평균 및 최선의 경우 시간복잡도 :O(nlog2n)
- 최악의 경우 시간복잡도 : O(n2)
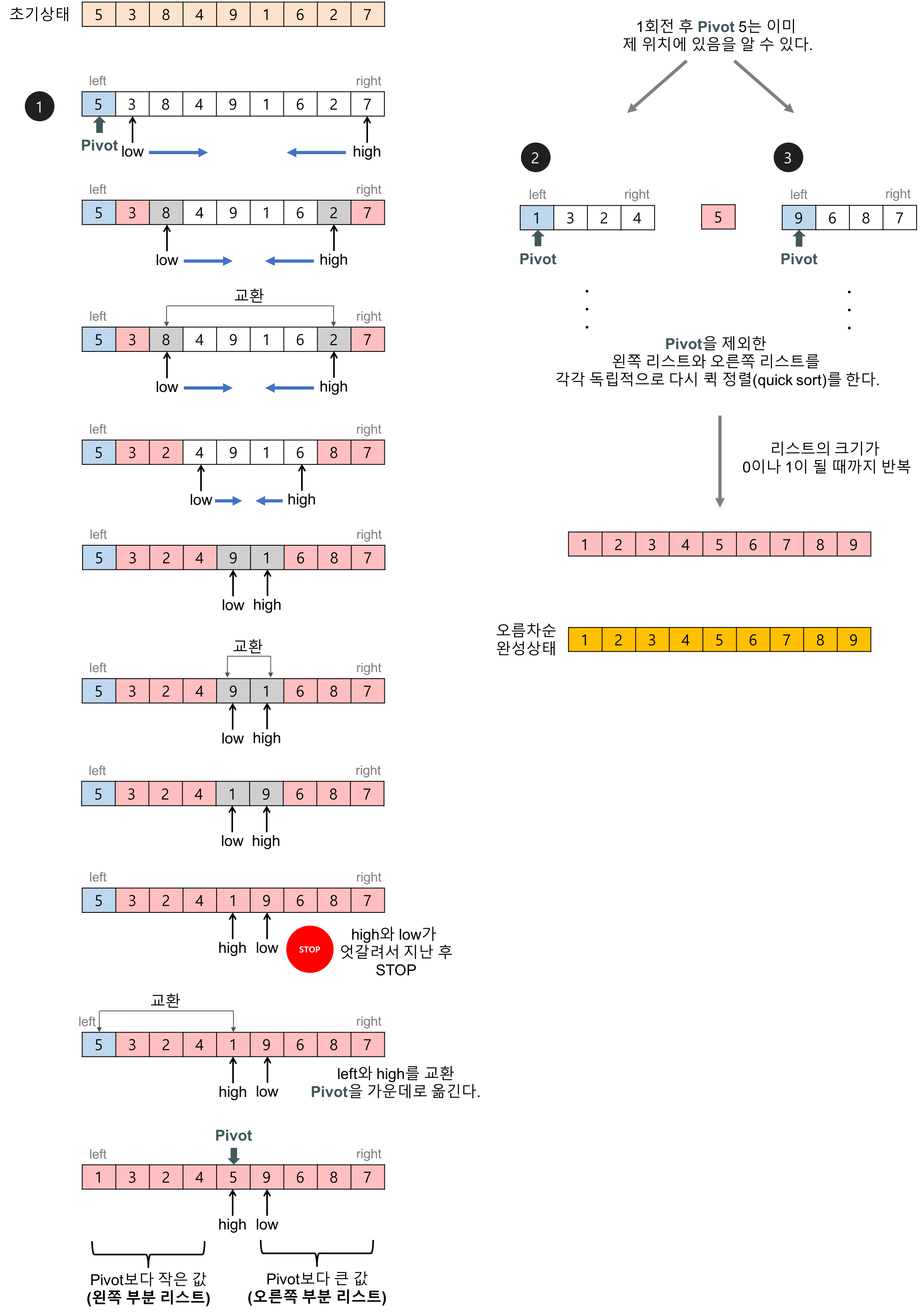
public void quickSort(int[] target, int start, int end) {
if (start >= end) return; // 원소가 1개인 경우 종료
int pivot = start;
int left = start + 1;
int right = end;
while (left <= right) {
// pivot보다 큰데이터를 찾을 때까지 반복
while (left <= end && target[left] <= target[pivot]) left++;
// pivot보다 작은데이터를 찾을 때까지 반복
while (right > start && target[right] >= target[pivot]) right--;
// 엇갈렸다면 작은데이터와 피벗을 교체
if (left > right) {
int temp = target[pivot];
target[pivot] = target[right];
target[right] = temp;
}
// 엇갈리지 않았다면 작은데이터와 큰 데이터를 교체
else {
int temp = target[left];
target[left] = target[right];
target[right] = temp;
}
}
// 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행
quickSort(target, start, right - 1);
quickSort(target, right + 1, end);
}
기수 정렬(Radix sort)
낮은 자릿수부터 비교하며 정렬한다. 비교 연산을 하지 않아 정렬속도가 빠르지만 데이터 전체 크기와 같은 메모리 공간을 추가로 필요로한다.

계수 정렬
특정한 조건이 부합할 때만 사용할 수 있지만 매우 빠르게 동작하는 정렬 알고리즘이다. 계수 정렬은 데이터의 크기 범위가 제한되어 정수 형태로 표현할 수 있을 때 사용 가능하다.
① 가장 작은 데이터부터 가장 큰 데이터까지의 범위가 모두 담길 수 있도록 리스트 생성
② 데이터를 하나씩 확인하며 데이터의 값과 동일한 인덱스의 데이터를 1 증가
③ 리스트의 첫 번째 데이터부터 하나씩 그 값만큼 반복하여 인덱스 출력
시간 복잡도는 O(N+K) 이다. 계수 정렬은 동일한 값을 가지는 데이터가 여러 개 등장할 때 효과적으로 사용할 수 있다.
public static void main(String[] args) throws IOException {
int n = 15;
int[] arr = {7,5,9,0,3,1,6,2,9,1,4,8,0,5,2};
int MAX_VALUE = Arrays.stream(arr).max().getAsInt();
int[] count = new int[MAX_VALUE + 1];
for (int i = 0; i < n; i++) {
count[arr[i]] += 1;
}
for (int i = 0; i <= MAX_VALUE; i++) {
for (int j = 0; j < count[i]; j++) {
System.out.println(i + " ");
}
}
}정렬 알고리즘 시간복잡도 비교

- 구현은 간단하지만 비효율적인 방식 : 버블 정렬, 선택 정렬, 삽입 정렬
- 구현은 복잡하지만 효율적인 방식 : 합병 정렬, 퀵 정렬, 기수 정렬
본 게시물의 GIF 파일의 출처는 https://hyo-ue4study.tistory.com/68
'Algorithm > 알고리즘' 카테고리의 다른 글
| [JAVA/알고리즘] 메모이제이션(Memoization) 개념과 예제 (0) | 2023.09.13 |
|---|---|
| [JAVA/알고리즘] 이진 탐색 알고리즘을 이용한 문제해결 (0) | 2023.09.12 |
| [JAVA/알고리즘] 이진 탐색(Binary Search) (0) | 2023.08.15 |
| [Java/알고리즘] 유클리드 호제법 - 최대공약수, 최소공배수 (0) | 2023.08.03 |
| [JAVA/알고리즘] 에라토스테네스의 체 (0) | 2023.07.18 |